
As developers, we’ve all been there: you need to share either parts of your code or sometimes your entire codebase with LLMs. The inspiration was…
Posts published by “Aryan”
Aryan is an editor and TechKnow Geek at Club TechKnowHow! He loves sharing cool stuff about tech and code in a way that's easy to understand and apply. Connect with him on LinkedIn & Instagram for updates and fun techie chats.🚀

Backing up a MySQL database running on production is crucial to ensure data integrity and availability. In the event of hardware failures, software bugs, human…

Over the weekend I was bored and tried hosting node applications on IIS on a server. Since currently I have only tried wordpress I had…

Recently, I was tasked with building a Chrome extension that scrapes LinkedIn profiles to gather important information such as name, bio, location, follower count, and…
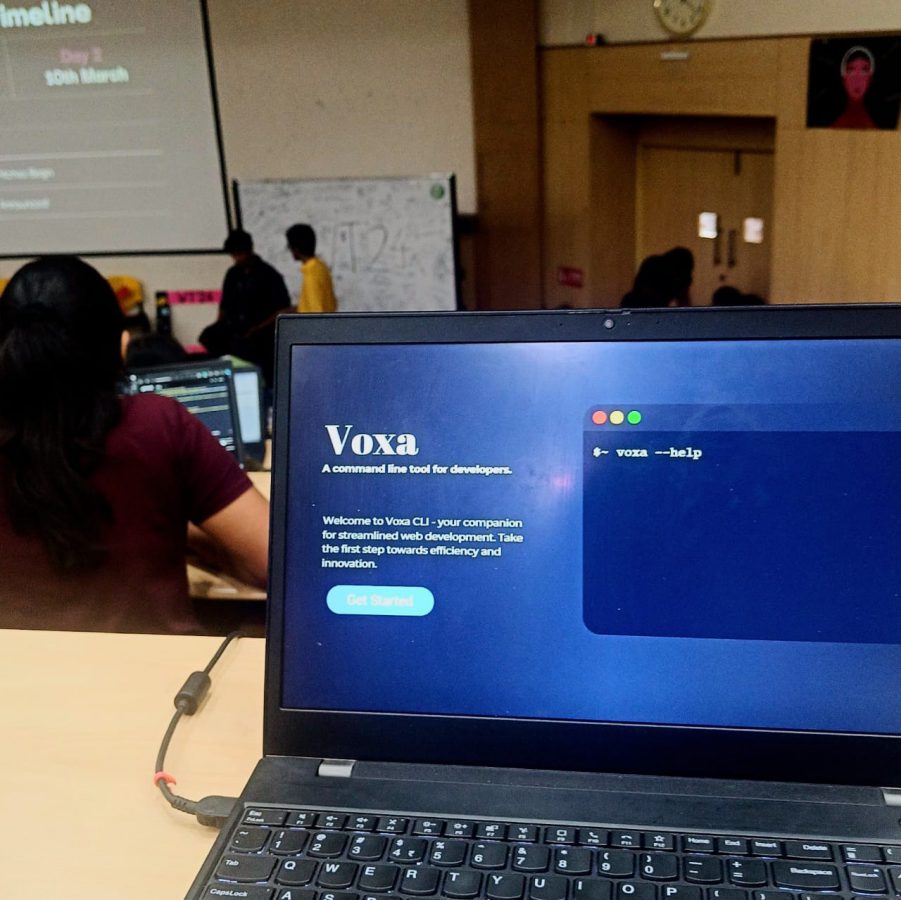
A while back, Prakriti and I participated in Women Techies, a hackathon at our university organized by the Google Developer Student Clubs at VIT Vellore.…