What is object recognition?
Before we delve into that, how do we identify images?
In a general sense, an object is any item, entity, or thing that can be perceived, identified, or defined. Objects have identifiable characteristics, such as shape, size, and color, which make them distinct from other objects.
IT IS THIS SET OF CHARACTERISTICS THAT IS EMPLOYED IN OBJECT RECOGNITION.
In the context of Artificial Intelligence (AI), particularly in computer vision, an object is a specific, identifiable part of an image or scene that the AI aims to recognize and classify. For example, in an image, objects could include things like a car, a person, a building, or a tree. Object recognition is the process by which an AI system detects these items in visual data, such as photos or videos, and identifies what they are.
In object recognition, the AI model processes visual data, identifies specific patterns and features (like edges, shapes, or textures), and classifies them as particular types of objects. Through training on large datasets, the model learns to recognize and label these objects across various scenes, angles, and conditions.
Healthcare: Object recognition helps analyze medical images to detect issues like tumors, improving diagnostic precision, and assists in patient monitoring to enhance safety.
Surveillance: It enables real-time detection of suspicious activities and unauthorized access, strengthening security, and aids in identity recognition for access control.
Autonomous Vehicles: Object recognition allows vehicles to detect pedestrians, road signs, and obstacles, enabling safe navigation and real-time decision-making in traffic.
Retail: It supports automated checkout by identifying items, streamlining the shopping experience, and improves inventory management by tracking stock on shelves.
Agriculture: Object recognition identifies crop health issues and weeds for precision farming, helping conserve resources and improve yield, and supports livestock monitoring.
Smart search engines
Object recognition enhances smart search engines by enabling visual search capabilities, where users can search with images rather than text. This technology recognizes objects within images and provides contextually relevant results, making searches more intuitive and accurate. For example, a user can upload a photo of a product, and the search engine identifies similar items or details. It also supports filtering results based on visual characteristics, improving the relevance of search outputs. Additionally, it helps identify landmarks, plants, or animals in images, offering useful information for educational or travel purposes.
Object recognition in smart search engines transforms browsing by making image-based searches more intuitive, allowing users to find information or products faster without needing precise keywords. In marketing, it personalizes user experiences by suggesting visually similar items, helping brands reach target audiences with relevant products. It enhances overall productivity by simplifying information retrieval, enabling faster decision-making and reducing time spent on searches. This technology also supports content creators and businesses by auto-tagging images and improving asset management. Ultimately, it aligns browsing, marketing, and productivity with a more visual, user-centric approach.
Services enabled by smart search engines
Google Lens uses object recognition to identify objects, text, and scenes in real-time through a smartphone camera, offering diverse services. It can translate text instantly by recognizing languages and overlaying translations on the screen, making it useful for travelers. Lens also provides shopping assistance by identifying products and suggesting similar items available online. Additionally, it recognizes plants, animals, and landmarks, offering educational insights or travel information. By turning a camera into an interactive tool, Google Lens makes everyday tasks like language translation, shopping, and learning more accessible and efficient.
Convolutional Neural Networks (CNN)
A Convolutional Neural Network (CNN) is a type of artificial intelligence model inspired by how the human brain processes visual information. It’s specifically designed to analyze data with a grid-like structure, like images or audio.
The CNN works by breaking down an image into small, manageable parts called “filters” or “kernels.” These filters slide over the image, focusing on small sections at a time. This process helps the network detect simple patterns, like edges or colors, in the early layers. As the information moves through deeper layers of the network, the CNN starts recognizing more complex patterns by combining the simpler ones, eventually forming a high-level understanding of what’s in the data.
Through many layers of filtering and pattern recognition, CNNs learn to identify features without requiring specific programming for each detail. This makes them great at spotting patterns in any type of visual or structured data, like sorting handwritten numbers, detecting textures, or analyzing medical scans.
A Convolutional Neural Network is like a digital artist that learns to see the world, recognizing patterns in pixels to transform raw data into understanding, one layer at a time.
Deep Learning & CNN
Deep learning is like teaching a computer by showing it tons of examples until it learns to make decisions on its own. It’s like when you learn what animals look like by seeing lots of pictures of them – after a while, you can tell a dog from a cat just by looking.
Deep learning is a type of AI where computers learn patterns by processing huge amounts of data through many layers, each layer building on the last. When combined with CNNs, deep learning helps computers analyze images by finding patterns in small parts first and then understanding the whole picture. Each layer in a CNN adds to this learning process, making the system more accurate and able to understand complex details.
Deep learning with CNNs is like teaching a computer to see, layer by layer, until it understands images the way we do, from simple edges to complex objects.
Deep learning is the art, and CNNs are the chisel—precision tools that carve raw data into clear vision.
Bias, data integrity and completeness
Object detection models can inherit biases from the training data, which may lead to inaccuracies or unfair predictions, especially if certain classes or demographics are underrepresented. For instance, if a dataset contains more images of certain objects or ethnicities, the model may perform better on those but poorly on others. This bias can have significant real-world implications, particularly in areas like security, healthcare, and autonomous driving, where fair and unbiased recognition is crucial.
To address bias in CNNs, diversify the training data to include various demographics and scenarios. Use data augmentation (flipping, rotating) to expand dataset diversity. Apply fairness-aware algorithms that re-weight classes or penalize biased errors. Transfer learning from a pre-trained, diverse model can also help reduce bias. Continuously evaluate the model across different groups and involve a diverse team to spot potential biases early.
Models – YOLO
YOLO (You Only Look Once) is a fast and efficient object detection model designed for real-time applications. Unlike traditional models that apply sliding windows or region proposals, YOLO treats object detection as a single regression problem, predicting bounding boxes and class probabilities directly from the full image in one pass. This approach allows YOLO to detect multiple objects in an image with high speed, making it ideal for applications requiring real-time detection, such as autonomous driving, surveillance, and robotics. YOLO’s architecture divides the image into a grid, where each cell predicts a set number of bounding boxes and confidence scores for object classes.. Additionally, by using a single neural network, YOLO avoids redundant computations, making it far more efficient than earlier region-based methods like R-CNN.

Models – resnet
ResNet (Residual Network) is a deep learning architecture designed to solve the problem of training very deep neural networks, which often suffer from vanishing gradients and accuracy degradation as layers increase. ResNet introduced residual connections, or “skip connections,” that allow the model to bypass certain layers. This innovation enables the network to pass information forward even if certain layers don’t contribute, making it possible to train networks with hundreds of layers effectively. each set of layers learns only the “residual” (or difference) between the input and the desired output rather than learning the full transformation. Mathematically, each residual block learns a function F(x) + x , where F(x) represents the transformation learned by the layers and x is the input passed directly to the output. This structure helps prevent gradient issues by maintaining a direct flow of information and gradients throughout the network.

Models – VGG

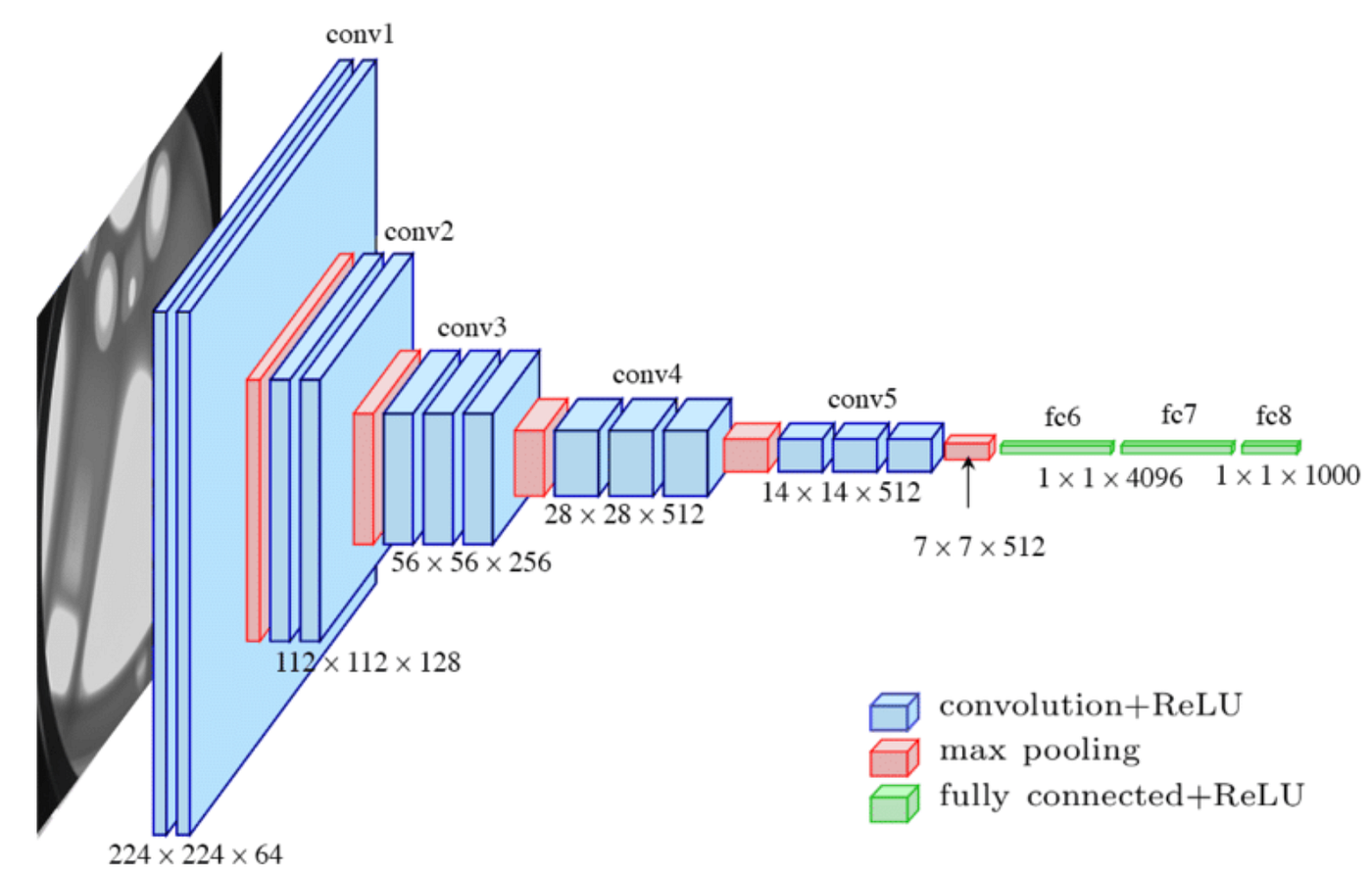
VGG-19 is a deep convolutional neural network (CNN) developed by the Visual Geometry Group (VGG) at the University of Oxford, introduced in 2014. Known for its simplicity and depth, VGG-19 contains 19 weight layers and performs exceptionally well on large-scale image recognition tasks like ImageNet.
- Convolutional Layers: 16 convolutional layers using 3×3 filters with stride 1 and padding 1, preserving spatial resolution.
- Activation Function: ReLU activation applied after each convolution layer to add non-linearity.
- Pooling Layers: Max-pooling (2×2 filters with stride 2) used after each convolution block to reduce spatial dimensions.
- Fully Connected Layers: 3 fully connected layers at the end for classification. Softmax Layer: For outputting class probabilities in multi-class tasks (e.g., 1000-class ImageNet classification).
Impact on Object Detection:
- Feature Extraction: The deep layers of VGG-19 are effective at extracting intricate features from images, making it highly useful for object detection tasks.
- Transfer Learning: Pre-trained VGG-19 models are widely used in transfer learning for object detection, where they are fine-tuned on domain-specific datasets.
- Influence on Modern Models: VGG-19’s architecture influenced models like ResNet and Inception, particularly its deep architecture and consistent use of small convolutional filters.
Why It’s Important:
Simplicity & Performance: The uniform structure of VGG-19, with its focus on small 3×3 filters, enables powerful feature learning that has become foundational in modern computer vision systems.
Recent Trends
Improvements
Accuracy Improvements: New architectures, like EfficientNet and ResNet, continue to push the boundaries in image recognition accuracy.
Self-Supervised Learning: Techniques that reduce dependency on large labeled datasets are emerging, potentially allowing models to learn from less annotated data, which saves time and cost.
Optimisation
Lightweight models like MobileNet and EfficientNet-Lite are optimized for devices with limited processing power, like smartphones. They maintain good accuracy while reducing size, memory, and computation needs, enabling real-time performance on mobile devices. These models use depthwise separable convolutions, breaking down standard convolutions into simpler steps to reduce parameters and computation. They also apply pruning (removing unnecessary weights) and quantization (using lower-precision data types) to cut down memory use. EfficientNet further optimizes by scaling depth, width, and resolution, balancing accuracy with efficiency for compact, resource-friendly deployments.
Be First to Comment